
Transport services and protocols
- 서로 다른 host에서 실행되는 application 프로세스 사이에 논리적인 통신연결을 만들어준다.(논리적인 선을 만들어주는게 X)
- transport 프로토콜은 end system 안에서 동작 (network core에선 구현 필요 X)
- sender (in application layer): segment 단위로 application message들을 쪼개서, network layer로 전송
- receiver (in transport layer): segment를 message로 재조립 후, application layer로 전송(어느 socket으로 보낼지 결정 후 전송)
- Internet application에서는 2개의 transport 프로토콜이 가능 (TCP, UDP)
ex) http 서버에서 client로 http response 메시지를 보낼 때 이 메시지는 object를 포함하므로 여러개의 segment로 쪼개야 한다.
Transport vs. network layer services and protocols
transport layer : 프로세스 사이에서 통신 (network layer에서 제공해주는 서비스에 의존하여 통신)
network layer : 호스트들 사이에서 통신
예를 들어서, Ann의 집에 12명의 아이들이 Bill의 집의 12명의 아이들에게 편지를 보낸다고 가정해보자.
host = 집
process = 아이들
app message = 봉투 안의 편지
transport 프로토콜 = Ann/Bill이 12명의 아이들에게 편지를 받은 후 Bill/Ann의 집에 보내줌.
network-layer protocol = Ann/Bill은 우편 서비스를 이용하여 편지 전송
Transport Layer Actions
Sender : Application-layer로부터 온 message에 segment header field 값들을 결정한 후 segment를 생성한다. 그 후, 이 segement를 IP에 전달한다.
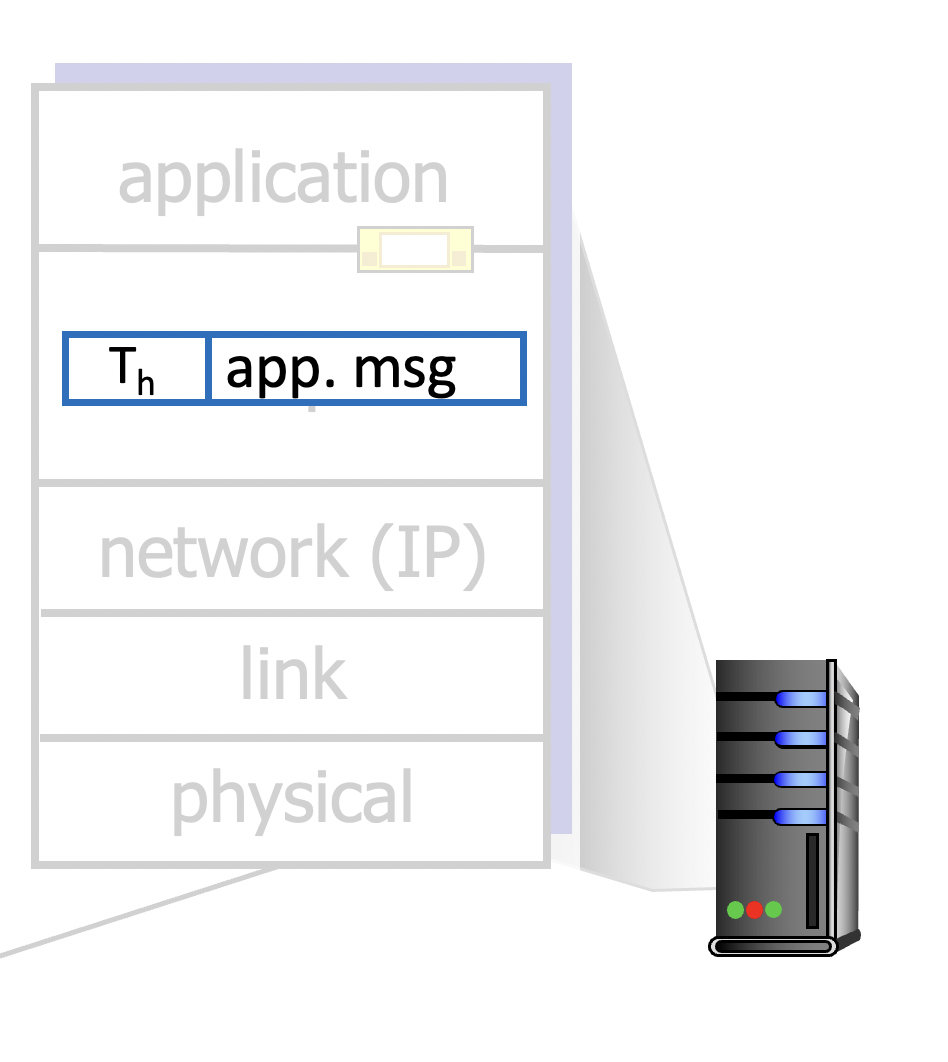
Receiver : IP로부터 segment를 받아, 헤더 값들을 체크한다. 그 후, application-layer의 메시지 부분만 추출하여 소켓을 통해 application까지 메시지를 전달한다. (demultiplex)


Two principal Internet transport protocols
TCP : Transmission Control Protocol
- reliable, in-order delivery
- congestion control
- flow control
- 미리 connection 생성 필요
- 전송 도중에 segment가 사라질 수도 있는데, TCP는 이를 복구해준다.
UDP : User Datagram Protocol
- unreliable, unordered delivery
- 추가적인 기능 확장이 없는 최선을 다하는 서비스(IP 그대로 사용 <TCP는 같은 내용을 가지고 여러개 지원하는 반면>)
- delay guarantees 보장 X (몇 ms 안에 보내야한다)
- bandwidth guaranteses 보장 X (segment를 보낼 때 100bps 내로 보내야 한다)
- 보내는 data가 가지 않을수도 O
Multiplexing/demultiplexing
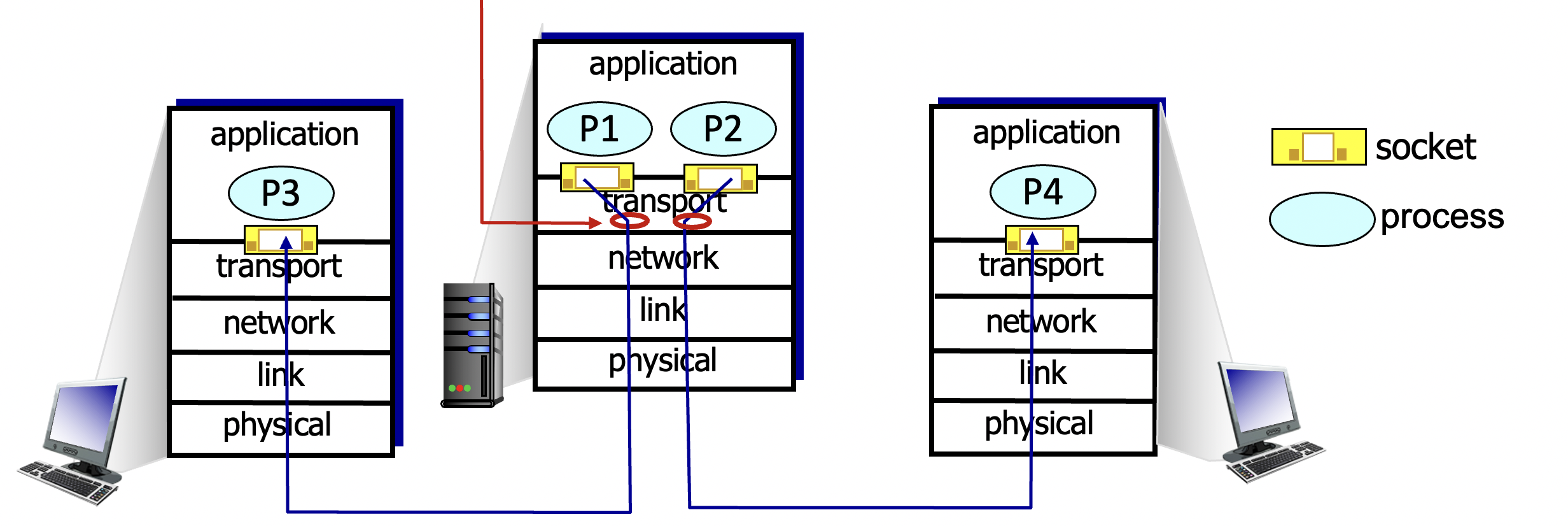
multiplexing at sender : 여러개의 소캣(각각의 프로세스가 생성한)으로부터 데이터(segment)를 받아, transport 헤더를 추가(나중에 demultiplexing에서 사용)
- transport layer는 network layer를 이용하여 메시지를 상대방 hsost에게 전송
- transport layer는 추가 정보를 segment 앞에 붙여서 전송 (받는쪽에서 정확하게 해당 프로세스에게 전달하기 위함.)

demultiplexing as receiver : 해당 segment를 받을 소켓에게 올바르게 전달하기 위해 헤더 정보 이용
- transport layer는 network layer를 통해 segment를 받는다.
- segment 앞의 헤더 정보를 통해 어떤 프로세스가 가진 소켓에게 전달할건지를 판단 후에 보내줌.
How demultiplexing works
- host는 IP datagram을 받는다.
- 각 datagram(network-layer packet)은 source IP 주소, destination IP주소를 보유
- 각 datagram은 하나의 transport-layer segment를 옮긴다.
- 각 segment는 source, destination port number를 가진다.(segment의 header에 포함)
- host는 IP address(network layer header) & port number(transpor layer header)를 사용하여 segment를 올바른 소켓에게 정확하게 보낼 수 있다.
- 즉, IP address를 사용하여 정확한 receving host에 도착 가능하고, 그 안에선 port #을 사용하여 host가 가진 어떤 소켓인지 파악 후에 정확하게 전달 가능하게 되는 것
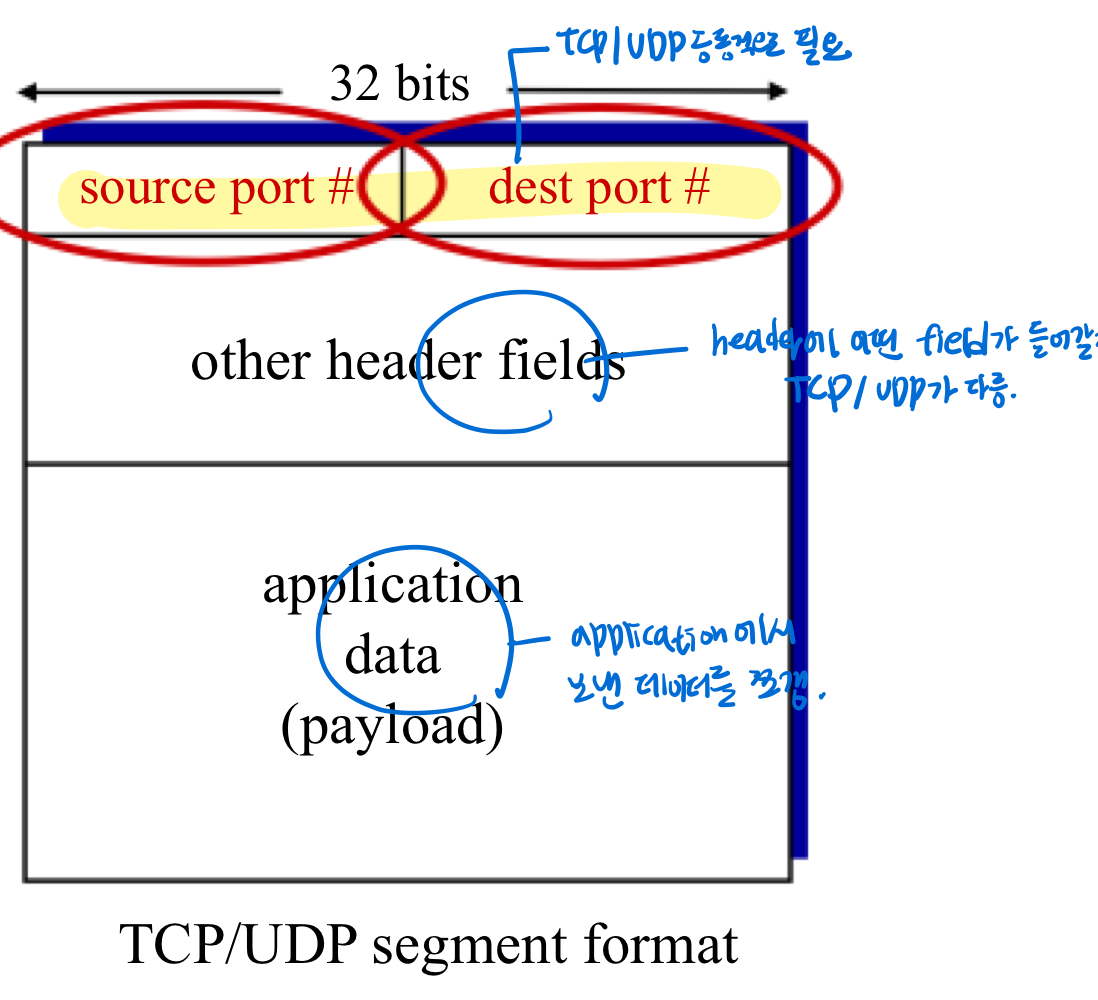
- demultiplexing 위해선 transport layer의 header에 있는 src/dst port# 중 dst port#를 사용하여 적절한 socket으로 보내줌.
- reply할 땐, src/dst port#가 dst/src port#로 바뀌어 응답해줌.
Connectionless demultiplexing - UDP에서 사용
sender
- host-local port#를 가지는 소켓을 생성한다.
DatagramSocket mySocket1 = new DatagramSocket(12534); // 12534로 오는 모든 packet은 이 소켓으로 전달
- UDP socket으로 보내는 datagram을 생성할 땐, destination IP address, destination port # 명시 필요 (datagram을 보낼때마다 명시 필요)
receiver
- host가 UDP segment를 받을 땐 destinatino port #를 확인하고, UDP segment를 해당 port #를 가지는 소켓으로 전달
- source IP address나 source port #가 다를 경우에도, destination port #가 같으면 항상 해당 port #를 가지는 소켓으로 전달
- 즉, 이 경우엔 src-dst에 지정되는 소켓이 없으며, src IP address/port #를 보지 X
Connectionless demultiplexing - 예시
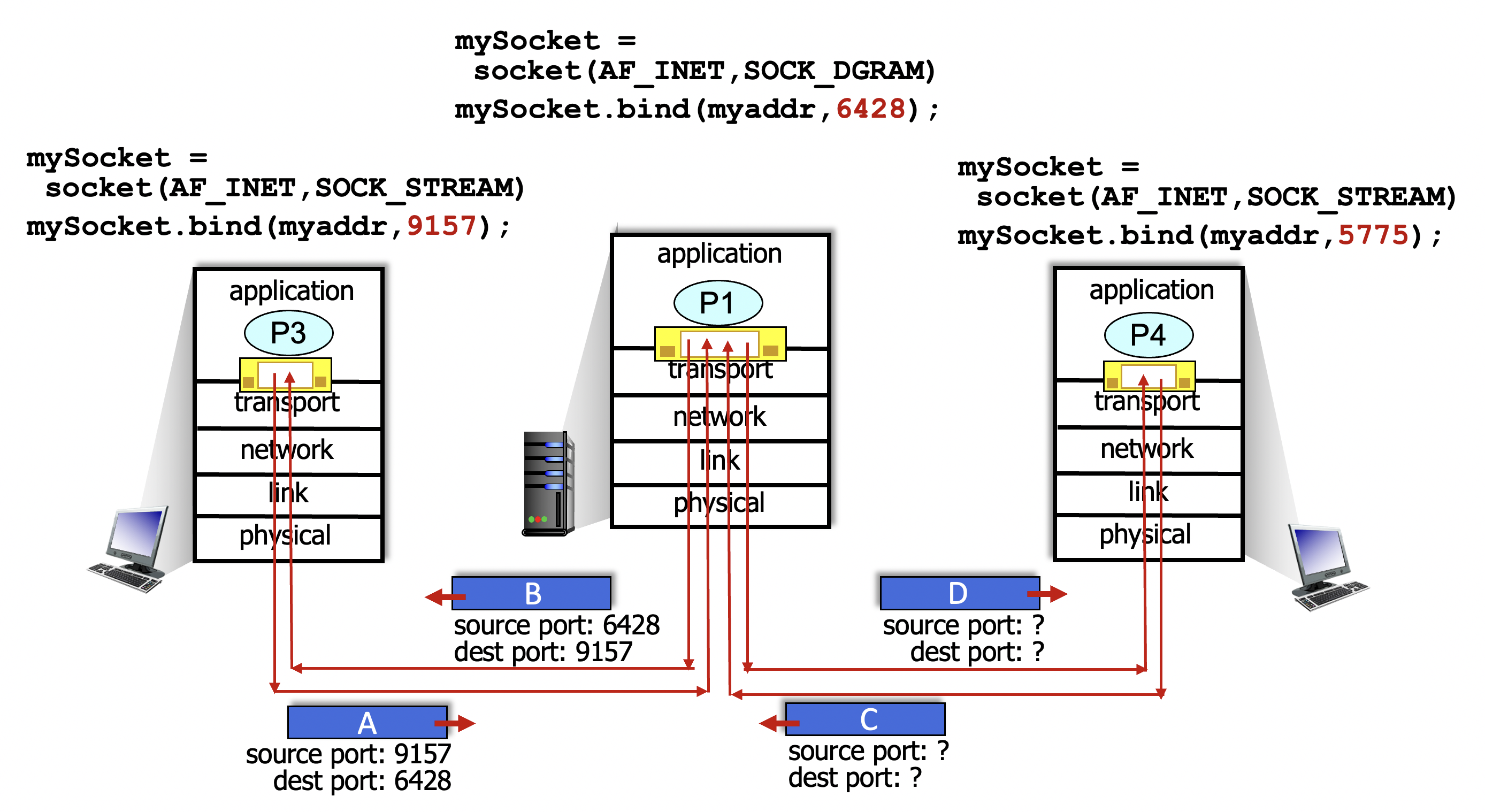
(1) src/dst IP address를 통해 network layer가 host에게 전달
(2) transport layer에선 dst port #를 보고, 6428에 해당하는 소켓을 찾는다.
(3) 6428과 binding 돼있는 소켓에 전달해준다.
-> 어디에서 오든간에 dst port #가 6428이면 항상 6428과 binding 된 소켓에 전달 (in transport layer)
Connection-oriented demultiplexing : src-dst간에 미리 연결 설정 필요
- TCP 소켓은 4-tuple 확인 후, 이 4가지가 모두 같은 segment만 해당 소켓으로 전달
- source IP address
- source port number
- dest IP address
- dest port number
demux: receiver(in transport layer)는 적절한 소켓에게 segment를 전달하기 위해 이 4가지 값들 모두 사용
cf ) connection-less에서는 dst port #과 dst IP address만 보면 됐음.
- 서버 프로세스는 동시에 여러개의 소켓 사용 가능 (연결이 여러개 들어와야하므로)
- 각각의 소켓은 4-tuple 중에 적어도 하나는 달라야함.
- client 하나하나마다 서로 다른 소켓 필요
ex) HTTP는 각각의 요청마다 서로 다른 소켓 사용
Connection-oriented

- 위에서, 3개의 segments는 모두 port # 80번을 사용 ( port #가 같아도 각기 다른 머신에 있기 때문에 상관 X, 4개의 값들 중 적어도 하나는 다를것이기 때문에 각기 다른 소켓 사용)
- 웹서버를 보통 만들면 프로세스 하나가 실행되다 80번으로 연결이 들어오면 fork()를 통해 자신과 같은 프로세스를 하나 더 생성 (소켓도 그대로 copy됨)
- 상대방 연결 요청이 들어왔을 때, src IP/port #가 다르기 때문에 p4, p5는 다른 소켓이 됨.
- 그냥 80번 port #으로 맨 처음 connection 요청이 들어오면 p4가 처음에 fork() -> p6도 새로운 소켓 생성(port # == 80)
- 4개의 쌍이 달라지기 때문에 p4 p5 p6 동시에 존재 가능
(But, 처음부터 p4 p5 p6 3개의 프로세스 실행시키면서 소켓 생성 후에 모두 # 80번으로 binding -> error)
요약
- Multiplexing과 demultiplexing은 각각 segment, datagram 헤더 값들에 기초
- Multiplexing과 demultiplexing은 모든 layer에서 발생
- UDP : destination port #만 오직 사용하여 demultiplexing
- TCP : 4개의 tuple(src IP address && dst IP address && src port # && dst port #)를 사용하여 demultiplexing
UDP - User Datagram Protocol
- UDP는 손실이 날수도 있고, 순서가 보장이 안된다.
- connectionless
- TCP는 client가 먼저 TCP connection을 생성하는데에 반해, UDP는 connection을 미리 만들지 X
- UDP sender와 receiver 사이에 주고받기 X
- 각각의 UDP segment는 독립적으로 처리
- 각각의 segment에 dst IP address && dst port # 꼭 필요
Q ) 그런데 UDP가 왜 존재 ?
A )
- RTT delay가 수반되는 connection 생성 과정이 필요 X
* TCP connection 생성 위해선 1RTT 필요

- sender와 receiver의 connection 상태가 필요 없기 때문에 단순
- TCP는 양쪽 소켓에서 현재 상태 저장 필요
- header size가 작음.
- UDP header : 8byte
- TCP header : 20byte
- congestion control이 없음.
- UDP는 원하는만큼 빨리 packet을 보낼 수 O
- TCP는 congestion 상태에 따라 속도를 마음대로 올릴 수 X
UDP - User Datagram Protocol
- streaming multimedia app
- loss에 관대, 속도 rate 보장해주는 앱에 많이 사용 -> 품질 저하가 나도 크게 문제 X
cf) TCP는 network에 congestion이 많이 발생하여 속도를 줄임.
- DNS
- 빠르게 IP address-hostname mapping 필요 -> 2RTT (connection 생성하는데 필요한) 필요 X
- SNMP
- 네트워크 라우터들 사이에서 발생하는 여러 에러 메시지/통계 등이 SNMP 프로토콜에 전달
-HTTP/3
- TCP와 UDP 중간의 단계가 필요하다 느껴 UDP에 추가 기능 구현하여 사용 (application layer 딴에서 구현)
UDP - User Datagram Protocol
- 과거에는 인터넷 상황도 별로 좋지 않고, bandwidth가 낮아서 packet loss가 많이 일어났다. 이상황에서 TCP까지 사용한더라면 이를 복구하기 위해 시간이 더 많이 걸렸을 것이기 때문에 UDP 많이 사용
- UDP에 추가 기능을 삽입하고 싶다면 application layer에 reliablity나 congestion control 구현해서 사용하면 됨.
- 위와 같이, 모두 text로 그려줘야 한다.
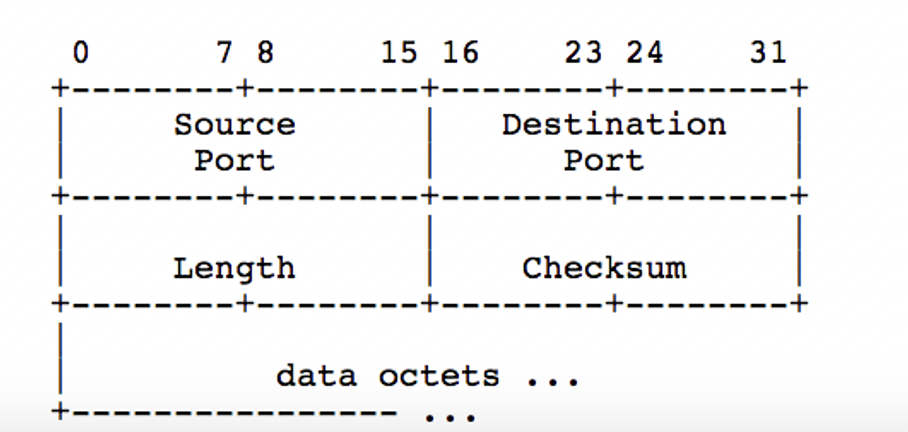
UDP segment header

UDP checksum
checksum : 전송된 segment에서 flipped된 bit가 있는지 에러를 감지하기 위해 사용

sender :
- UDP header와 IP 주소들 즉, 16bit integer의 나열인 UDP segment의 내용을 다룸.
- segment의 내용(이러한 bit들)을 더하여 checksum value값 생성
- checksum value를 UDP checksum field에 추가
receiver :
- 받은 segment에 대해서 checksum 계산 후 계산된 checksum이 checksum field에 있는 값과 같은지 비교
- 즉, receiver의 checksum과 sender의 checksum이 같은지 비교
- != : 에러 감지 (But, 어디서 에러 났는지 detect는 불가)
- == : 에러 X
Internet checksum
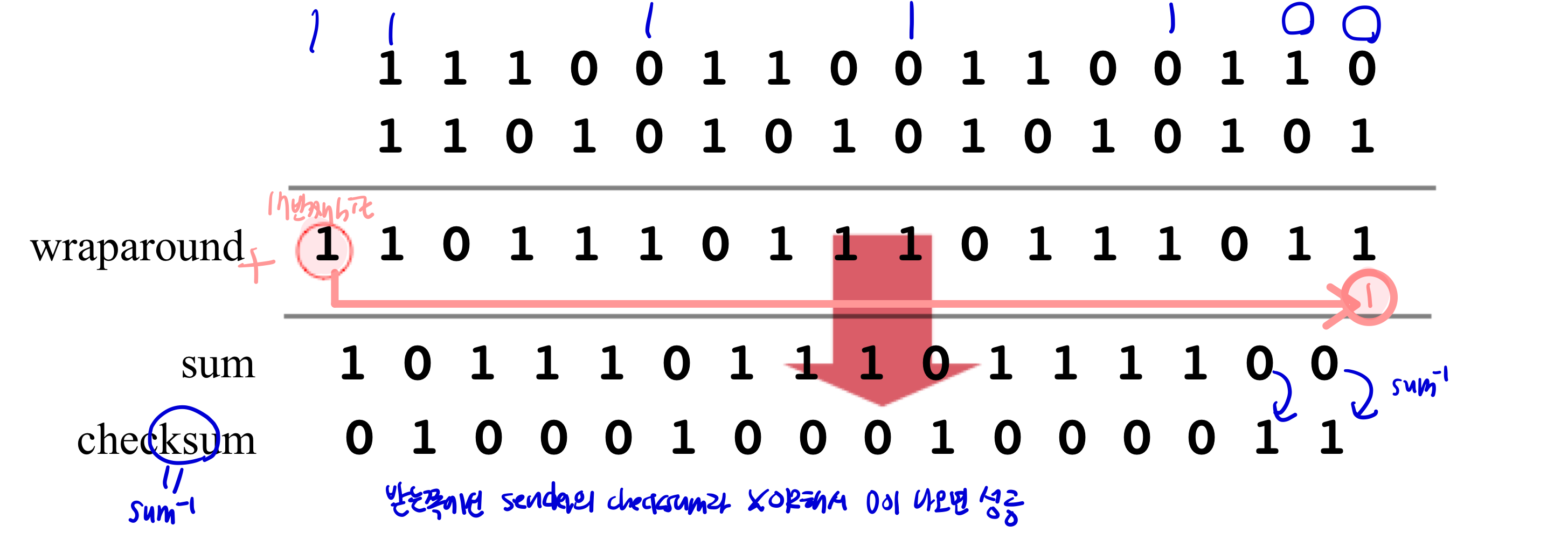
- 1의 갯수가 홀수개이면 XOR 했을 때 결과값이 1이 나옴.
- 따라서, XOR 했을 때 값이 0이 나오면 checksum 값이 동일한것
Internet checksum - 문제점

- 같은 위치에 있는 bit가 위아래로 서로 flip된 경우, detect불가 (결과적으로 sum값이 그전과 같기 때문)
- 어떤 방법이든 모든 에러를 다 감지하는건 불가하긴 함.
Principles of reliable data transfer

reliable : 데이터를 보낼 때 손실 없이 정확한 순서로, congestion control (혼잡할 땐 packet 덜 보내는 등 ..)
- transport layer가 reliable 서비스 제공해준다 가정 -> 내가 보낸 data가 그대로 잘 전달
- But, 우리가 쓰는 link/채널이 unreliable하더라도 TCP는 reliable을 제공해줘야 함 !

- 따라서, sender와 receiver쪽에 모두 reliable data transfer protocol 구현 필요
- reliable data transfer protocol 의 협업을 통해 중간에 unreliable한 network layer에서 bit가 사라지더라도 복구 가능
- reliable data transfer protocol 의 복잡도는 unreliable channel의 특성에 의존
- if) channel이 많은 일 수행해주면 reliable data transfer protocol 간단하게 구현 가능
Q) 그렇다면, sender와 receiver는 각각의 상태에 대해 어떻게 알까 ?
- sender : receiver가 메시지를 잘 받았는지
- receiver : sender가 data를 보냈는지 / 보냈는데 내가 못받은건지 등 ..
A) 메시지를 통해 소통하지 않는 한 모른다. 따라서, state 정보 또한 메시지로 보냄으로써 확인해야 함. But, 이 state 정보를 담은 메시지가 잘 도착했는진 또 알 수 X
Reliable data transfer protocol (rdt) : interfaces

sender :
(1) application. layer에서 rdt_send() 함수로 data를 보냄.
(2) reliable data transfer protocol에서 추가적인 정보 추가
(3) reliable data transfer protocol에서 udt_send() 함수를 호출해 packet 전송
- udt_send : network-layer에서 제공
receiver :
(1) rdt_rcv() : 받은 packet을 transport layer에 전달
(2) reliable data transfer protocol을 동작하며 packet 검사
(3) 이상 없으면 reliable data transfer protocol에서 deliver_data() 호출
(4) packet application layer로 전송
+) reliable data transfer 추가 링크

우선 패킷을 송신하는 경우,
상위의 application layer에서 보내려는 데이터가 있을 경우 rdt_send() 시스템 콜을 호출하여 RDT 프로토콜로 전송한다.
RDT 프로토콜에서 신뢰할 수 없는 채널인 하위의 network layer로 보낼 때 udt_send() 를 호출해 패킷을 전송한다.
또한 패킷을 수신하는 경우,
하위의 network layer에서 보내려는 패킷이 있을 경우 rdt_rcv() 시스템 콜을 호출하여 RDT 프로토콜로 전송한다.
RDT 프로토콜에서상위의 application layer로 데이터를 보낼 경우 deliver_data() 를 호출해 데이터를 전송한다.
https://ddongwon.tistory.com/80
Reliable data transfer (rdt 1.0/3.0)
1. Reliable Data Transfer 신뢰성 있는 데이터 교환(이하 RDT)은 한마디로 "송/수신하는 데이터가 오류없이 온전히 전송되는 것" 이다. Transport Layer 에서는 신뢰성 있는 데이터 교환을 하고싶어 하지만,
ddongwon.tistory.com
Reliable data transfer protocol
- data transfer은 오직 일방향(sender->receiver)만 고려할 것
-But, control info 정보는 양방향 ! (packet 손실이 났는지 등을 알려줘야 하기 때문)
- 각각의 상태를 FSM을 통해 나타내볼 것
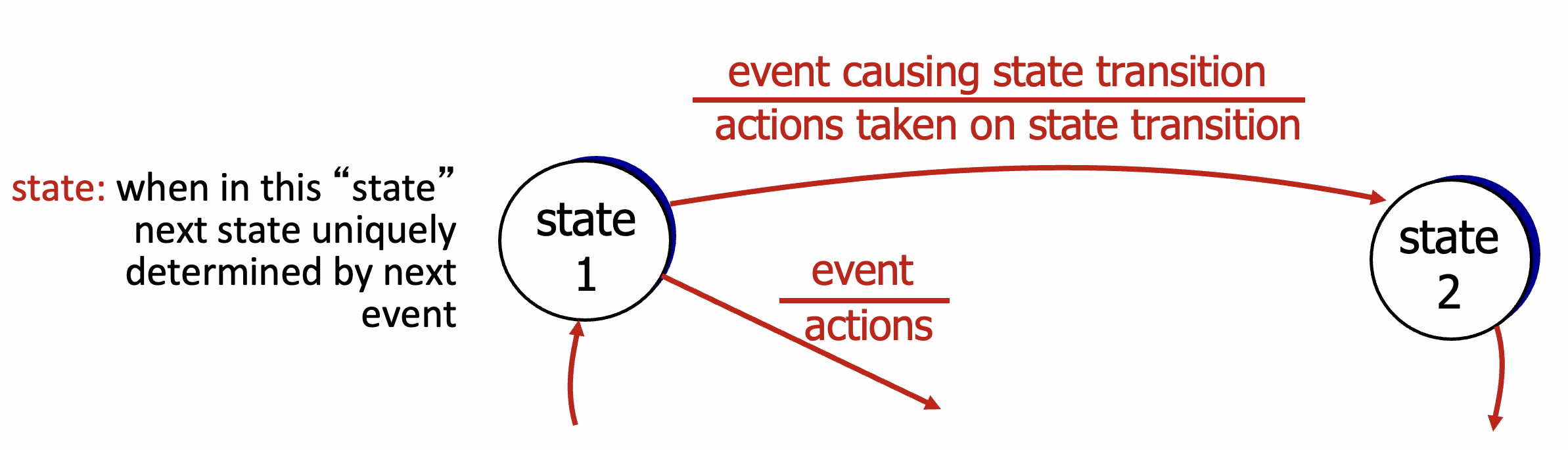
rdt1.0 : reliable transfer over a reliable channel
- 완벽하게 reliable한 channel에 놓여있다 가정
- bit error 없음.
- 패킷 loss 없음.
- 보내는쪽과 받는쪽에 각각 분리된 FSM

rdt2.0 : channel with bit errors -> checksum 추가
- packet 안에서 bit가 flip될 수도 있는 channel에 놓여있다 가정
- bit error만 존재
- 패킷 loss는 없음.
--> checksum을 이용해 bit error를 감지하자 !
--> packet을 만들어서 전송 시 checksum 값을 꼭 넣어줘야함.
Q) checksum을 통해 bit error가 났다는 걸 알면 어떻게 recover?
A)
- sender가 retransmission(재전송) 필요 !
- 여기선 receiving에서의 역할이 중요해짐.
acknowledgements(ACKs-control info<부가 정보>) : receiver -> sender에게 pkt received OK 상태를 전달
negative acknowledgements(NAKs) : receiver->sender에게 pkt had errors 상태를 전달
- sender는 NAK를 받으면 재전송 필요
- error가 O/X 정보만 알려줌. (어느 bit가 문제가 있는진 알 수 X)
- 재전송해도 에러가 날 수 O -> 또 보내야함.
stop and wait : sender가 packet 하나를 보내고, receiver로부터 응답(ACKs/NAKs)을 받을때까지 기다림. 즉, receiver가 응답을 보내줄때까지 sender가 그 다음 packet을 보내지 않고 기다림


-> receiver가 sender에게 메시지를 받은 상태를 알려주지 않으면 sender는 알 방법이 X. 이것이 프로토콜이 필요한 이유
rdt2.0 : scenerario
(1) no error sceneario
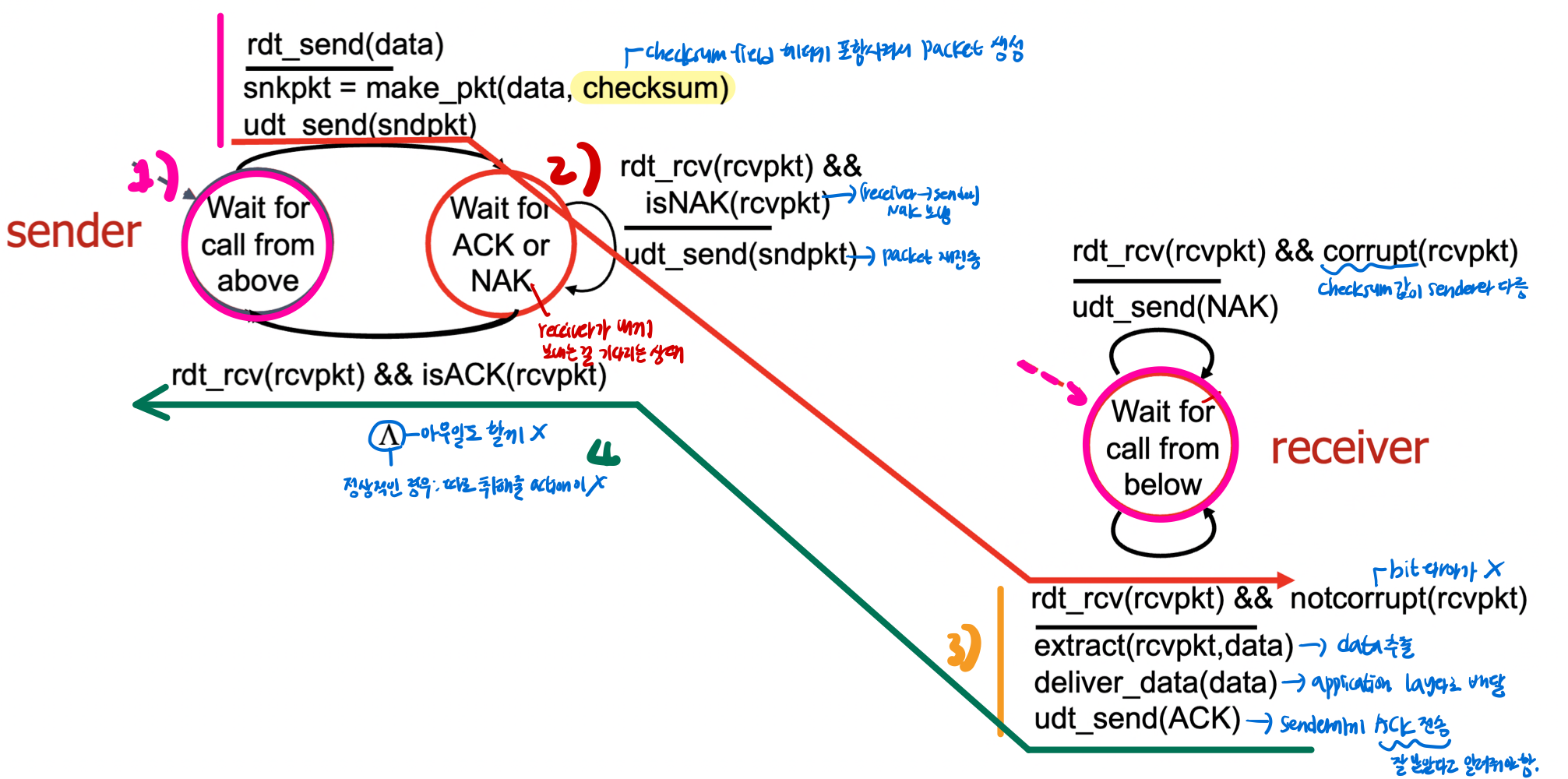
(2) corrupted packet sceneario

- bit error가 있는 상황에서도 정상적으로 data 전송 가능
rdt2.0 : 치명적인 문제점
Q) 만약 ACK/NAK도 bit error가 나면 어떡함?
-bit error : ACK/NAK인데 NAK/ACK로 가는 경우
ACK/NAK 메시지인지도 구분이 안가는 경우 --> 무조건 NAK라 판단 후 재전송 필요
A) sender는 receiver에게 어떤 일이 발생했는지 모르므로 재전송할 수 밖에 없음 -> duplicate이 될수도 O
▪︎ duplicate 처리하기
- ACK/NAK를 보낼때도 checksum을 포함해서 보내야함.
- 만약 ACK/NAK에 bit error가 나면 sender는 현재 packet 재전송 필요- sender는 각 packet에 sequence number 추가
- duplicate 해결하기 위해 헤더에 field 추가할 필요 O
- 실제 application layer에서 보내준 data에서 같은 내용이 반복되는 경우(같은 내용의 packet이 생성됨)와 duplicate이 일어나 같은 내용의 packet이 생성되는 경우를 구분하기 위함.
- receiver는 duplicate packet(sequence #가 동일한)을 버림으로써 application layer에 전달 X
rdt2.1 : (sender) ACK/NAK인지 구분 못하는 경우 처리 -> sequence number 추가
- bit error (1) data packet에 대한
(2) ACK/NAK에 대한
- sequence number를 0,1,0,1 순으로 붙혀서 보낸다고 가정해보자.

rdt2.1 : (receiver) ACK/NAK인지 구분 못하는 경우 처리 -> sequence number 추가
- bit error (1) data packet에 대한
(2) ACK/NAK에 대한
- sequence number를 0,1,0,1 순으로 붙혀서 보낸다고 가정해보자.
- rdt 2.0과 다르게 receiver는 ACK/NAK를 보낼 때에도 checksum 값을 붙혀서 보내야 한다.

rdt2.1 : 요약
▪︎ sender :
- seq #를 packet에 추가
- 두개의 seq # (0,1)도 충분
- 현재/과거에 보낸 packet만 구분하면 되기 때문
- 0번 보내고 잘 도착했는지 확인 후 1번 보내기 등 반복
- duplicate가 발생하는 이유는 과거에 보냈던걸 또 보내거나, 과거에 받았던걸 또 받은 경우이므로 과거에 보낸 것과 지금 보내려는 것과 구분할 수 있으면 됨.
- ACK/NAK에 에러가 있는지도 확인 필요 (ACK/NAK의 checksum값을 통해 sender쪽에서 비교)
▪︎ receiver :
- 받은 packet이 duplicate됐는지 확인 필요
- 내가 받으려는 packet의 seq #가 0/1인지에 따라 다른 처리 필요
- receiver는 자신이 마지막에 보낸 ACK/NAK를 sender가 잘 받았는지에 대해 알지 못한다. -> 상태 2개 필요
rdt2.2 : a NAK-free protocol (NAK 사용하지 않는 버전)
- rdt 2.1과 같은 기능을 하는데, ACK만을 사용해서 수행
- NAK 대신, receiver는 마지막으로 정상적으로 받은 packet에 대한 ACK를 보낸다.
- receiver가 ACK를 보낼 때 정확하게 어떤 seq #를 가진 packet인지 명시 필요
- NAK처럼 동작하는 duplicate ACK(같은 packet에 대한 ACK를 여러번 받음-->문제가 생긴 경우)를 받은 sender는 현재 보내고자 하는 packet을 재전송해줘야 함.
ex) 0번 packet을 보내고 0번에 대한 ACK를 받음 --> 0번 OK
그리고, 1번에 대한 packet을 보냈는데 0번에 대한 ACK를 받음 --> sender는 1번 packet 재전송 필요
rdt2.2 : (sender,receiver) a NAK-free protocol -> NAK 사용 X
- bit error (1) data packet에 대한
(2) ACK/NAK에 대한
- NAK를 사용하는 부분만 바뀌면 된다.
- rdt 2.1과는 다르게 receiver쪽에서 ACK를 보낼 때 어떤 seq #의 packet인지 명시 필요
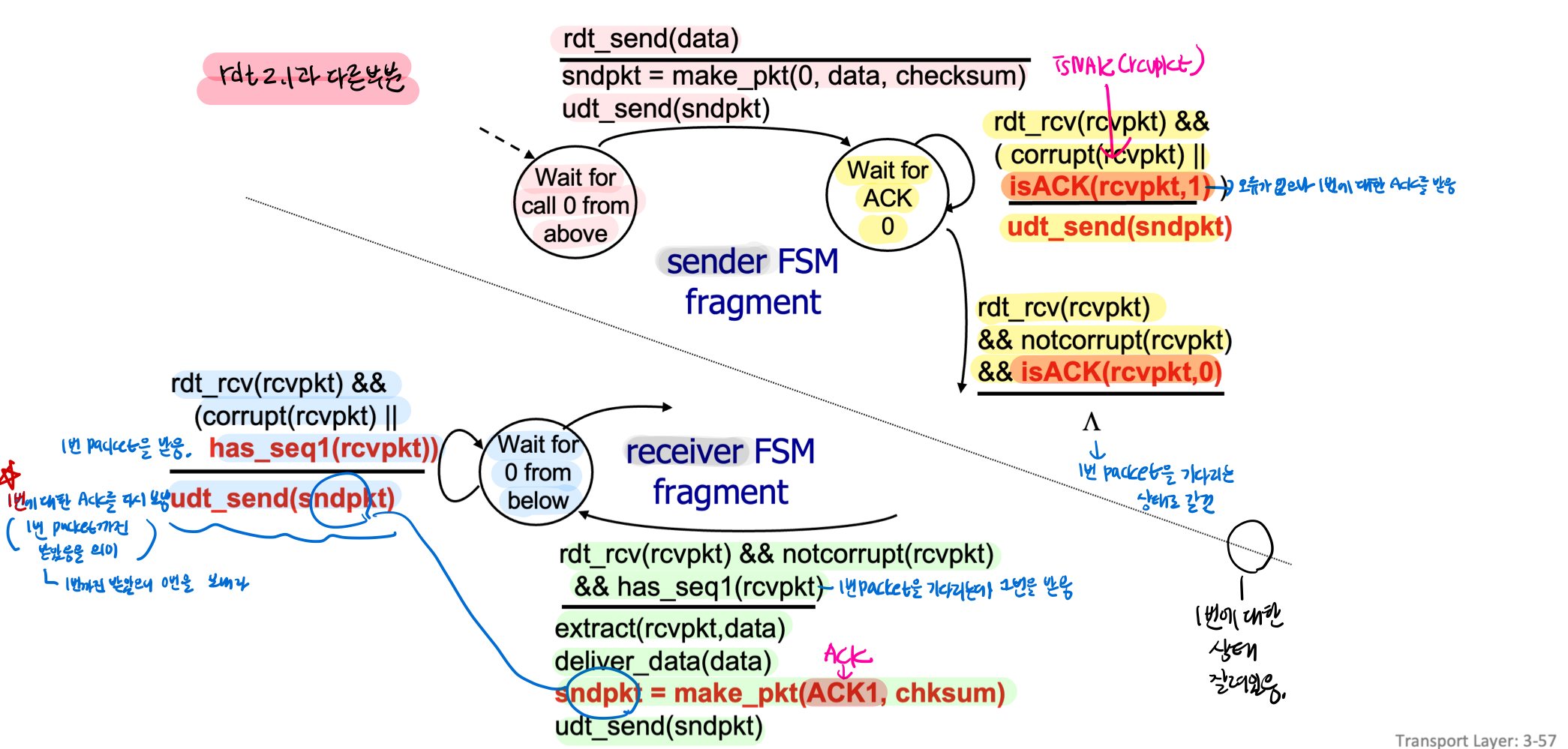
rdt3.0 : channels with errors and loss
- bit error (1) data packet에 대한
(2) ACK/NAK에 대한
- packet loss (1) data packet에 대한
(2) ACK/NAK에 대한 (아예 packet이 안갔으므로 ACK도 안감 -> 재전송 불가)
Q) 일정 시간 기다렸는데, 아무 response X에는 어떻게 함 ?
- (1) packet loss 난 경우 (2) ACK loss 난 경우
A)
sender가 ACK를 위해 일정시간 기다린 경우
- 이번 시간에 받은 ACK가 없다면 재전송
- data나 ACK에 대한 packet이 단지 지연되는 경우 (loss X)
- 재전송하면 duplicate이 될것이지만, seq #를 부여해서 이미 처리했기때문에 노상관
- 따라서, receiver는 반드시 어떤 seq #의 packet에 대한 ACK를 보내는지 명시 필요
- 합리적인 시간 할당량 이후엔 timer를 사용해서 interrupt
rdt3.0 : (sender) time out 발생시에만 재전송하게 만듦.
- bit error 존재
- packet loss 존재
- packet(data) / ACK loss 둘다 time out 사용

rdt3.0 : (receiver) -> rdt 2.0 그대로 사용
- receiver 입장에선 time out에 의해 재전송된 패킷인지, ACK에서 corrupt가 일어나 재전송된 패킷인지 구분할 필요 X
rdt3.0 in action
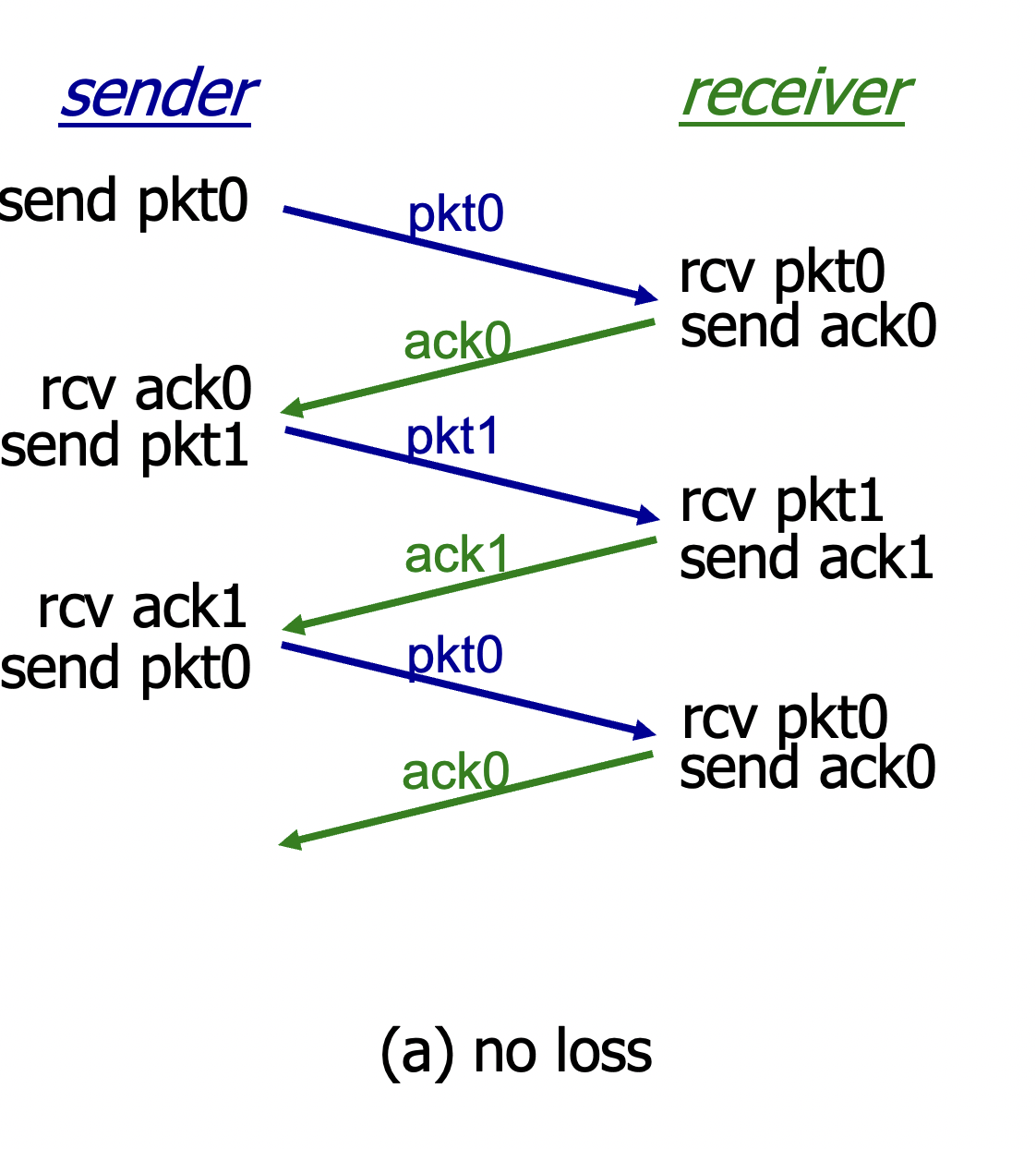

(a) no loss
(b) packet loss
- receiver 입장에선 중간에 packet loss가 발생한건지 안한건지 알 수 X
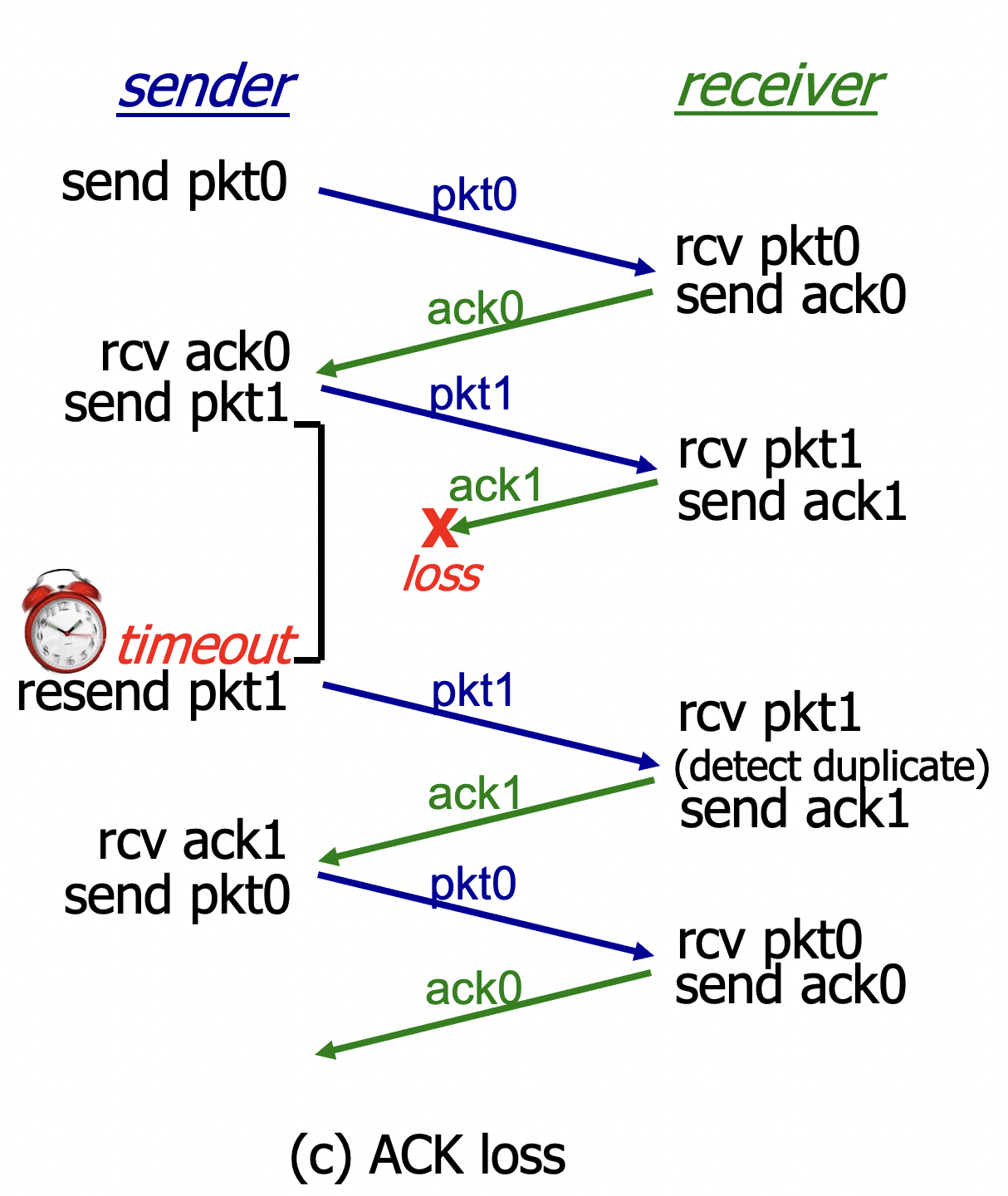
(c) ACK loss
- sender 입장에선 나의 packet loss인지 ACK loss인지 알 수 X -> packet1을 재전송할 수 밖에 없음.
- receiver 입장에서 packet이 duplicate됐음을 알게 되고, ACK1을 다시 보내줌.
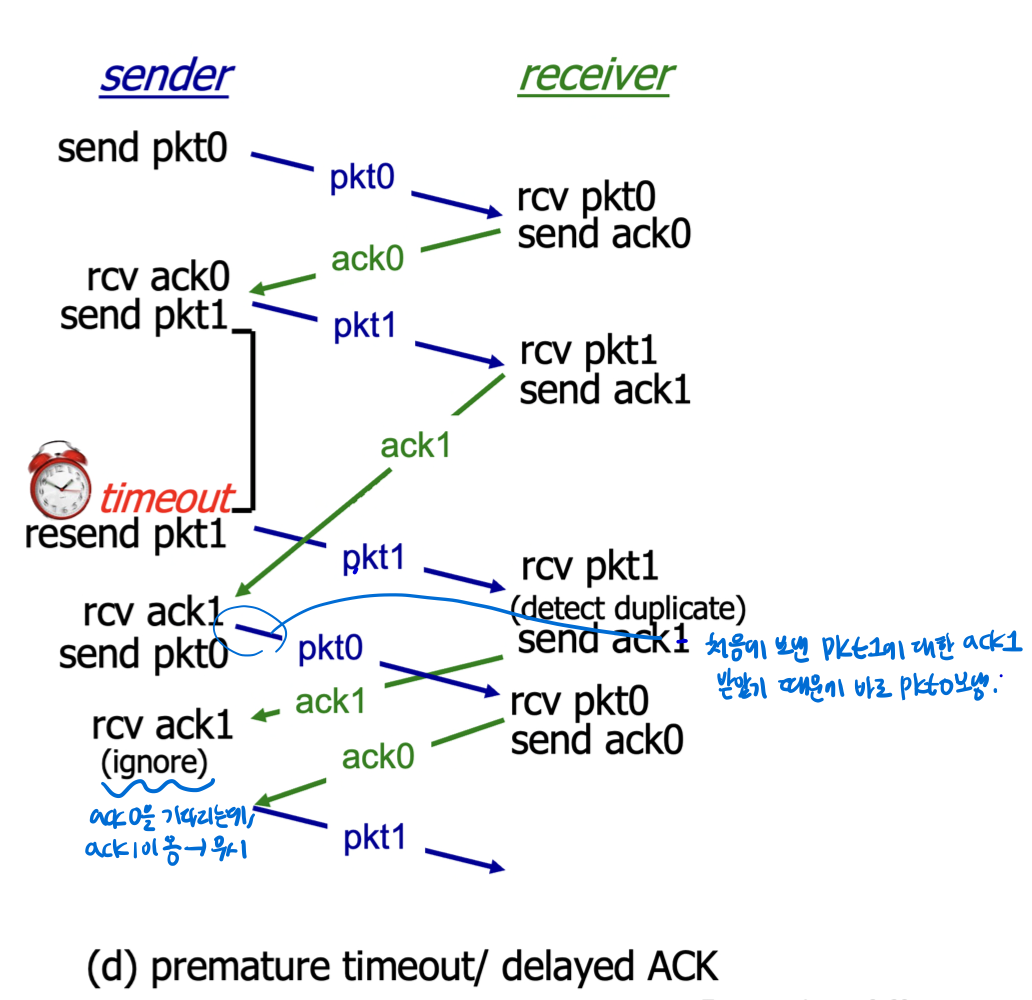
(d) premature timeout/delayed ACK (아무 손실이 없었는데 단지 delay돼서 재전송하는 경우)
- sender 입장에선 pkt1 loss/ACK1 loss/ACK가 오고있는지 알 수 없기 때문에 일정 시간이 지나면 재전송
rdt3.0의 성능 (stop-and-wait : sender가 pkt1을 보낸 후에 ACK1을 받을 때까지 아무일X)
U sender: utilization(사용률) - 전체 시간 중에 sender가 얼마만큼 데이터를 보내는데 사용하는지 - 높을수록 좋음.(sender가 많이 안놀고 있단 뜻)
ex) 1Gbps link, 15 ms propogation delay, 8000bit packet
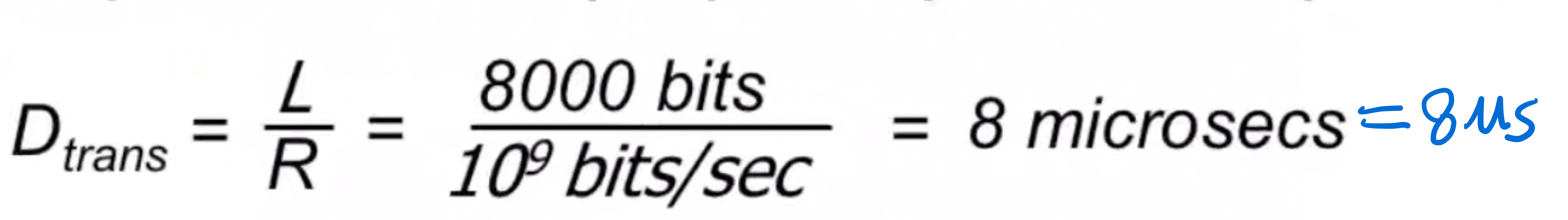

- packet을 보낸 후, receiver로부터 ACK를 받아야하므로 RTT = 15ms *2 = 30msec - ACK의 transmission rate은 여기서 없다고 가정.
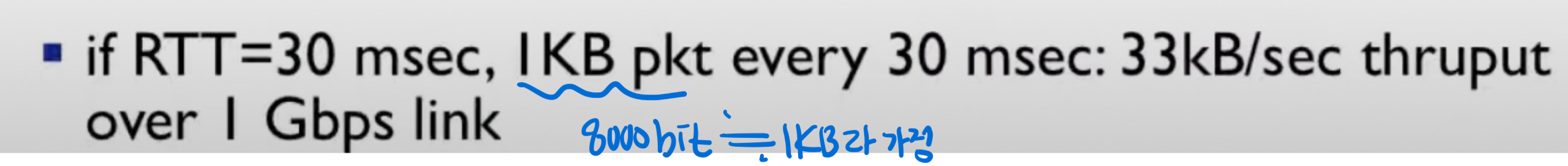
- > 우리는 packet size가 8000bit(대략 1KB라 가정)인 packet을 보낼 때, 30.008msec가 듦. -> 33KB/1sec --> 내가 가진 link의 bandwidth는 1Gbps인데, 1초에 33KB밖에 못보내므로 낭비가 심함. -> network protocol(rdt 3.0)이 물리적인 자원(link)의 사용을 제한하고있음.

-> rdt 3.0 프로토콜은 성능이 좋지 X
rdt3.0 : pipelined protocols operation
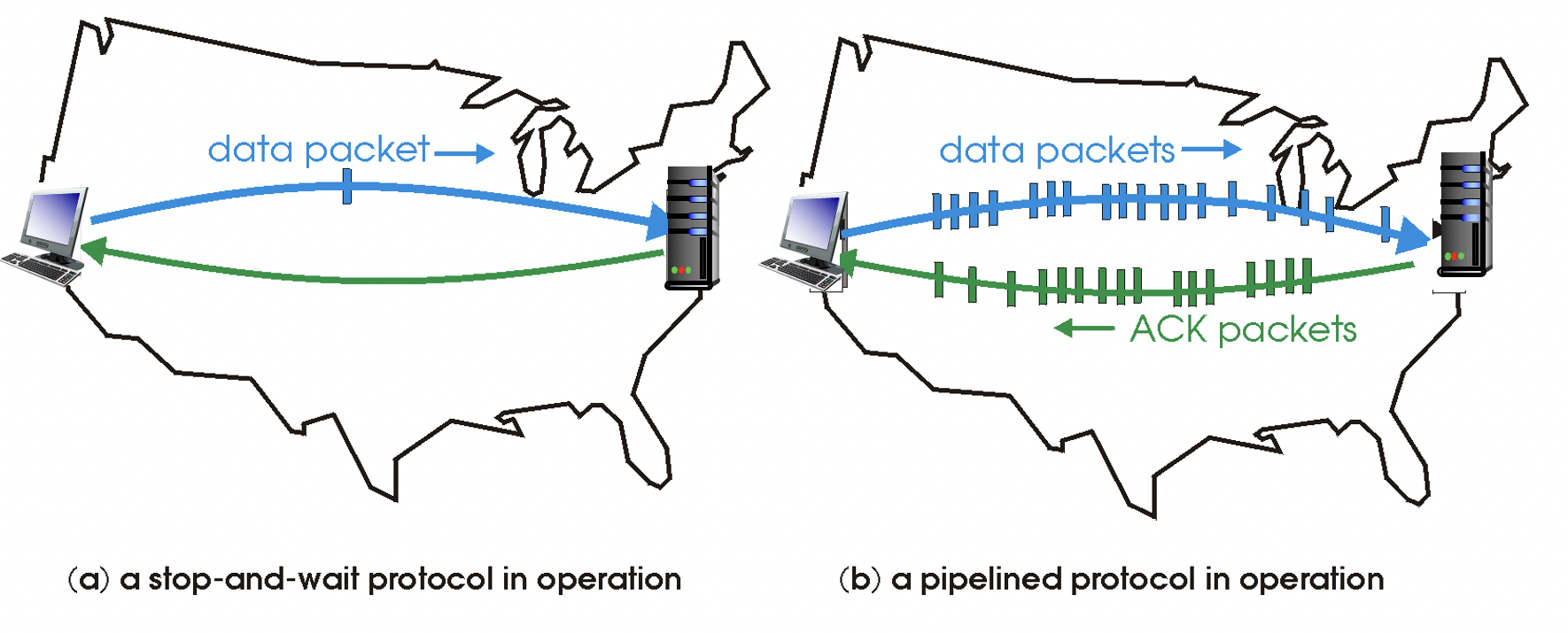
pipelining : ACK를 아직 받지도 못했는데, 그 다음 packet들을 보냄.
- IDLE한 시간이 줄어듦.
- sequence number의 범위가 늘어나야함. (ACK를 받지 않은 상태에서도 packet 보내야하기 때문)
- sender와 receiver 사이에 버퍼링 필요
- pipelined protocol의 대표적인 2가지 (1) go-Back-N (2) selective repeat
pipelined가 utilization을 증가시킬 수 있는 이유
-sender가 ACK를 받지 않고, 최대 packet 3개까지 보낼 수 있다 가정하자.

'Computer Science > Computer Network' 카테고리의 다른 글
| Chapter3 - GoBackN과 Selective Repeat (0) | 2023.04.25 |
|---|---|
| Chapter 1 - application layer (0) | 2023.04.14 |
| HTTP 응답코드 종류 (0) | 2023.03.06 |